Overview
AcquireSpeech is the integrated speech recognition interface for the Toolkit. AcquireSpeech provides real time monitoring, transcripts, and recording, as well as allowing for direct text input and playback of recorded speech samples. It has been designed with a focus on configurability and usability, allowing for different speech recognition systems and usage scenarios. AcquireSpeech is not a speech recognizer itself, but a tool that connects the sound input on your computer to the included speech recognition server. By default, the Toolkit uses PocketSphinx, but AcquireSpeech is compatible with a number of ASR systems.
Quick facts:
- Location: /core/acquirespeech
- Language: Java
- Distribution: Binary
Platform(s): Multi-platform
Users
AcquireSpeech is the key component for interacting with the Toolkit. AcquireSpeech is designed for use with a microphone, but also supports text input of user speech and the use of prerecorded speech samples.
Launching AcquireSpeech
AcquireSpeech launches by default when 'Launch', under the 'Run It All' group in the Virtual Humans Launcher, is pressed.
To launch AcquireSpeech manually, expand the Launcher options with the 'Advanced' button and press 'Launch' which is found next to 'Speech Recognition' in the 'Input/Output' tab. This will launch both the PocketSphinx Wrapper and AcquireSpeech. Typically, there is a slight delay while PocketSphinx loads before AcquireSpeech connects to it.
Setting up a Microphone
AcquireSpeech is configured to automatically select your default audio input on start and usually does not require manual configuration. However, it can be configured by either a configuration file or the Settings Tab.
Speaking to a Character
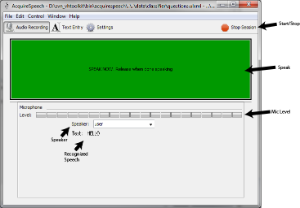 The Recorder tab is the primary interface for AcquireSpeech. Go there to start a session, monitor your microphone level, and/or trigger recording with the press-to-talk 'Speak' button.
The Recorder tab is the primary interface for AcquireSpeech. Go there to start a session, monitor your microphone level, and/or trigger recording with the press-to-talk 'Speak' button.
To start an AcquireSpeech session, click the green 'Start Session' button in the upper right, or Ctrl+r. Once the session has started, the large 'Speak' button in the top of the tab will brighten and become interactive. When depressed, the 'Speak' button turns bright green.
To say something to the Toolkit, press the 'Speak' button and hold it down while speaking. The horizontal level meter shows the input levels as you speak. The meter indicates the correct level with green; if there is a lot of red or yellow, try turning down the microphone volume. When finished speaking, release the button. The utterances spoken, or the ASR's best guess, will appear in the 'Text' area below. The speaker can be changed with the drop down box, if necessary. The default is "user" throughout the Toolkit.
To lock the mouse to the 'Speak' button, such as during a presentation, press Ctrl+m. This will also unlock the cursor when you are finished. When the mouse is locked, the 'Speak' button darkens, to either dark gray or dark green.
To stop a session, either to end a Toolkit session or to change settings, click the red 'Stop Session' button.
Configuring AcquireSpeech
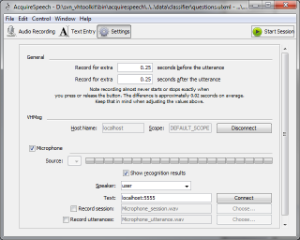
- General Settings includes the recording time before and after the "Speak" button is pressed; default is .25 seconds. This added time allows AcquireSpeech to capture the entire spoken utterance bracketed by silence or background noise without requiring any special action from the user.
- VHMSG Settings covers how AcquireSpeech interacts with other components. For most users, the Server and Scope will be filled in automatically with the values "localhost" and "DEFAULT_SCOPE", respectively. We do not recommend changing these values without referring to the expanded documentation.
- Microphone Settings are the bottom block and cover the sound setup for AcquireSpeech. The Microphone check box at the top should be checked, indicating a microphone will be used. The sound input can be changed with the drop down box, but the default setting should work for most users. If AcquireSpeech isn't hearing you, try a different input or microphone. If no options are presented in the drop down, please check that your microphone is connected and working properly in your OS's configuration tool.
- Show recognition results toggles display of the recognition feedback from Pocket Sphinx, or whichever recognition server is connected, underneath the 'Speak' button in the Recording Tab. 'Default speaker' is used to connect to NPCEditor, and supports multiple speakers. The speaker here should match the 'Agent Name' in the "Smartbody" account in 'People' > 'Accounts' of NPCEditor.
- Record Session and Record Utterances toggle recording of the user's speech. The session recording is of everything said into the microphone from when an AcquireSpeech session is started. Utterances are split recordings from when the 'Speak' button is depressed.
Message API
Receives
vrAllCall
Broadcasts AcquireSpeech VHMsg ID. It is set to asr.
vrKillComponent (all | asr)
Stops AcquireSpeech. If the recording is running, AcquireSpeech will attempt to shut it down gracefully.
acquireSpeech action action description in xml
Tell AcquireSpeech to perform the specified action. The action xml schema can be found insrc/java/acquirespeech.xsd. It takes two attributes:
1. targetComponentID defines the component to apply this action to; if the ID is missing, the action is applied to the overall model structure
2. command defines the action command; see the list of action commands for the complete reference
Output
AcquireSpeech sends out events transmitting recognition result and notifications about the state of recording
vrSpeech
see vrSpeech documentation
acquireSpeech startedListening inputComponentID sessionID utteranceID recordingTimeInMilliseconds
This message is sent when an utterance recording starts.
acquireSpeech stoppedListening inputComponentID sessionID utteranceID recordingTimeInMilliseconds
This message is sent when an utterance recording stops.
acquireSpeech info message
This message is sent when a group component selection is changed.
acquireSpeech startedSession inputComponentID sessionID timeInMilliseconds
This message is sent when a session recording starts.
acquireSpeech stoppedSession inputComponentID sessionID timeInMilliseconds
This message is sent when a session recording stops.
Known Issues
FAQ
See main FAQ.