Introduction
the process of creating a character is iterative in nature. The following steps create an initial character that will probably need to be refined by repeating the steps as required to obtain the desired behavior.
Three actions are required to create the content necessary to drive the natural language component:
- Create an initial set of system and user utterances. Each utterance needs to be associated to an identifying string (like a name) and the natural language understanding and dialogue management modules will use these identifiers instead of the real utterances.
- Create a dialogue policy. This policy consists of:
- the set of variables that constitute the dialogue state (the dialogue manager is an information based one. That is it decides what to say based on what the user said and the current state of the conversation as represented in the dialogue state (also called information state)).
- the set of sub-dialogue networks. These sub-dialogues are similar to planning operators, with preconditions and effects. The dialogue manager (DM), will select one based on what the user said and the current dialogue state. Each sub-dialogue typically carries out a short portion of an entire dialogue (e.g. the greeting phase, or answering a question).
- Train the natural language understanding module to map a given utterance to one of the known identifying strings defined in the first step.
The entire information that defines a character, e.g. CakeVendor, for the FLoReS system is defined in a set of files sitting in the directory resources/characters/CakeVendor/
This directory contains three sub-directories that parallel the 3 steps defined above:
- content: this directory contains the files that define the user and system utterances and their identifying strings.
- dm: this directory contains the dialogue policy
- nlu: this directory contains the natural language understanding model learned by the corresponding module from the data in the data found in the content directory.
Step 1: Authoring the content
Authoring the content consists of editing 2 files. One for the user utterances and one for the system utterances. The file that contains the user utterances is basically the training data for the natural language understanding (NLU) module. The system utterance file instead contains the utterances that the character can say.
User utterances:
The NLU module given an utterance returns the most probably identifying strings. It's based on a maximum entropy multiclass classifier and therefore the user utterance file should list utterances maintaining their natural frequency. That is, the best way to obtain these utterances is by running wizard of oz experiments or role plays. Then annotate the data by assigning to each utterance said by a user during these experiments an identifying string. These identifying strings are sometime called speech acts or dialogue acts (in case more domain specific semantic is attached to the basic speech act). Examples of dialogue acts are: question.age to mark all utterances in which the user is asking about the age of the addressee.
When we design a dialogue policy for the character using this content, whenever we want to wait for the user to say a certain utterance, we will use the string identifier (speech act) associated to that utterance.
System utterances:
These utterances are the one the system can say. Similarly to the user utterances, each utterance has a specific string identifier. When designing the dialogue policy, if we want to say a certain system utterance, we will use the corresponding identifier (also here called speech act).
File format:
The user and system utterances files use the same Excel spreadsheet format. These files have a number of columns (these are the initial 2 rows of the system utterances file for the character used in the example below):
| TTERANCE_ID | VERSION | CHARACTER | STATE | SPEECH_ACT | TEXT |
| statement.not-understand | I'm sorry, I didn't understand what you said. Please try to rephrase it. | ||||
| greeting.hello | Hello |
The only 2 columns of relevance are SPEECH_ACT and TEXT.
SPEECH_ACT contains the string identifier for the corresponding utterance found in the TEXT column.
The user utterance file needs to be called user-utterances.xlsx and the system utterance file must be called system-utterances.xlsx (these names can be configured, but the default configuration looks for those names in each character available).
Step 2: Authoring the dialogue policy
Overview
The FLoReS (Forward Locking Reward Seeking) dialogue manager is an information state and event driven dialogue manager. That is it does nothing unless an event is received. When an event is received it searches for the best action (i.e. sub-dialogue) that can be executed in the current information state and that achieves the highest expected reward. Once the best action is found it start executing it. Unless:
- the current action in execution is the same as the best action found. In that case the dialogue manager simply continues to execute the action.
- there is no best action. That can happen in 2 cases:
- there are no actions that can be executed given the current event and information state.
- all executable actions have negative expected rewards
As mentioned earlier the dialogue manager searches for the best available action every time an event comes in.
Actions are also called sub-dialogues and define dialogue trees. For example this is one sub-dialogue found in the CakeVendor example below:
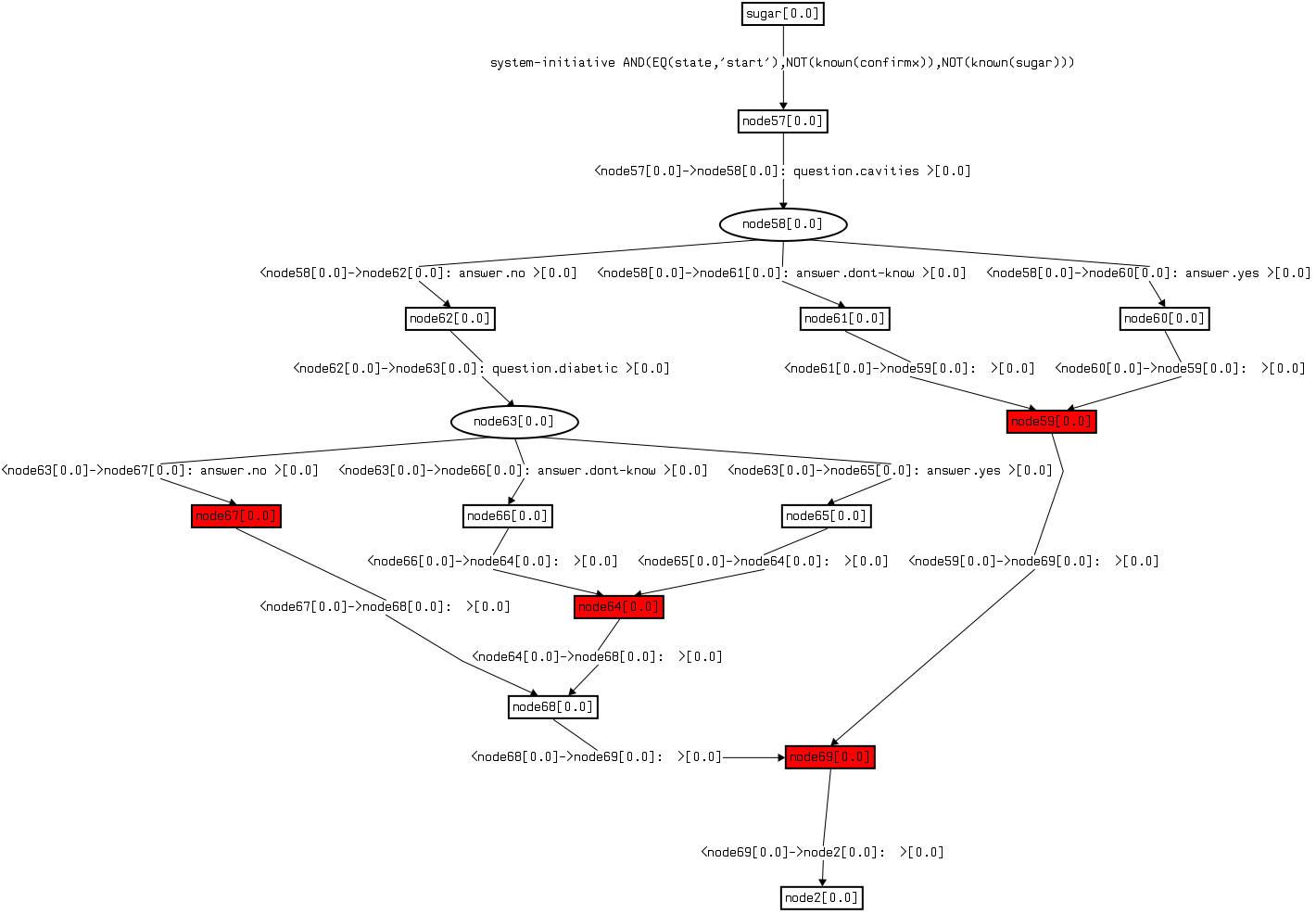
These sub-dialogue trees define a small self-contained portion of conversation. the criteria to use to decide what should be a sub-dialogue is similar to the criteria used to decide what should be a function or method in a programming language: generality and reusability.
For example, the sub-dialogue above takes care of finding out whether the system can sell to the user a cake with normal sugar or with Xylitol based on collecting information about the user having many cavities or having diabetes. Because the utterances found in this sub-dialogue can happen only in that specific context, then it makes sense to keep them in the same sub-dialogue.
A sub-dialogue can be in 3 states: ACTIVE, INACTIVE and DORMANT.
At any time in the system there is at most 1 active sub-dialogue: the current action. As said above, in some cases there may be no active actions. All actions are normally inactive, unless they have been active and they have been substituted (swapped-out) by another action before their natural termination (that is, at some point the system found a better action and so changed the state of the current action to dormant and made the newly found best action as active). Not all actions that are active and are swapped out for a new best action can become dormant. Some will go back directly to the inactive state. An action, to be allowed to become dormant, must have special entry paths that allow for it to be awoken back to the active state in case it becomes again the best action.
A sub-dialogue has multiple entry paths. The entry paths have a specific order (decided by the author) and each entry path has conditions to regulate when it can be taken and has also a start state. That is when the system during the search for the best available action considers a certain sub-dialogue, it'll considers all the possible entry paths in the order specified. The first that has satisfied conditions will be taken and it'll start the execution of the action at the specified start state in the sub-dialogue tree.
The possible types of entry paths are:
- user event entry paths: a user event entry path defines an entry path that can be taken only when certain specified events are received. A user event entry path can also have an optional condition on the information state. This optional condition is a Boolean expression of information state variables.
- system initiative entry paths: these entry paths have no events associated with them. They can have optional information state condition as for the user entry paths. These entry paths are used to give to a certain sub-dialogue the possibility of being initiated by the system no matter what event has been received. For example one can define a periodic timer event that wakes-up the dialogue manager periodically even if the user is inactive.
- re-entry paths
The policy format
The dialogue policy is composed by several files. The main file that defines it is called policy.xml (also this name can be configured, but this is the default name).
A typical policy.xml file will look like the following:
<policy xmlns:xi="http://www.w3.org/2001/XInclude"> <xi:include href="initKB.xml"/> <xi:include href="goals.xml"/> <stepDiscount value="0.9"/> <include href="textFormat/policy.txt"/> </policy>
line 2 specifies the file used to define all the variables in the information state and to initialize them.
line 3 specifies the
Step 3: Train the natural language understanding module
An example
CakeVendor.zip contains all is required to define a CakeVendor character that is an extension of the character created in this other tutorial for NPCEditor.